

Why RoboInF
If you are training a vision-language-action model today, your data options are limited. Real robot teleoperation produces high-quality trajectories but scales slowly and covers narrow task distributions. Internet videos are abundant but lack ground-truth actions, and bridging the embodiment gap remains an open problem [1][2][3][4]. The result is a practical bottleneck: generalist manipulation policies need data that is simultaneously diverse in scenes, natural in language, spatially precise, and physically varied -- and most existing pipelines deliver only one or two of those properties at a time.
Modern VLA models have shown increasingly impressive long-horizon behavior, from household tasks to cooking-style demonstrations [5][6]. Those demonstrations make the data problem more urgent, not less. Generalist manipulation needs training data that covers richer scenes, natural language variation, fine-grained spatial control, and perturbations that do not appear in narrow benchmark distributions.
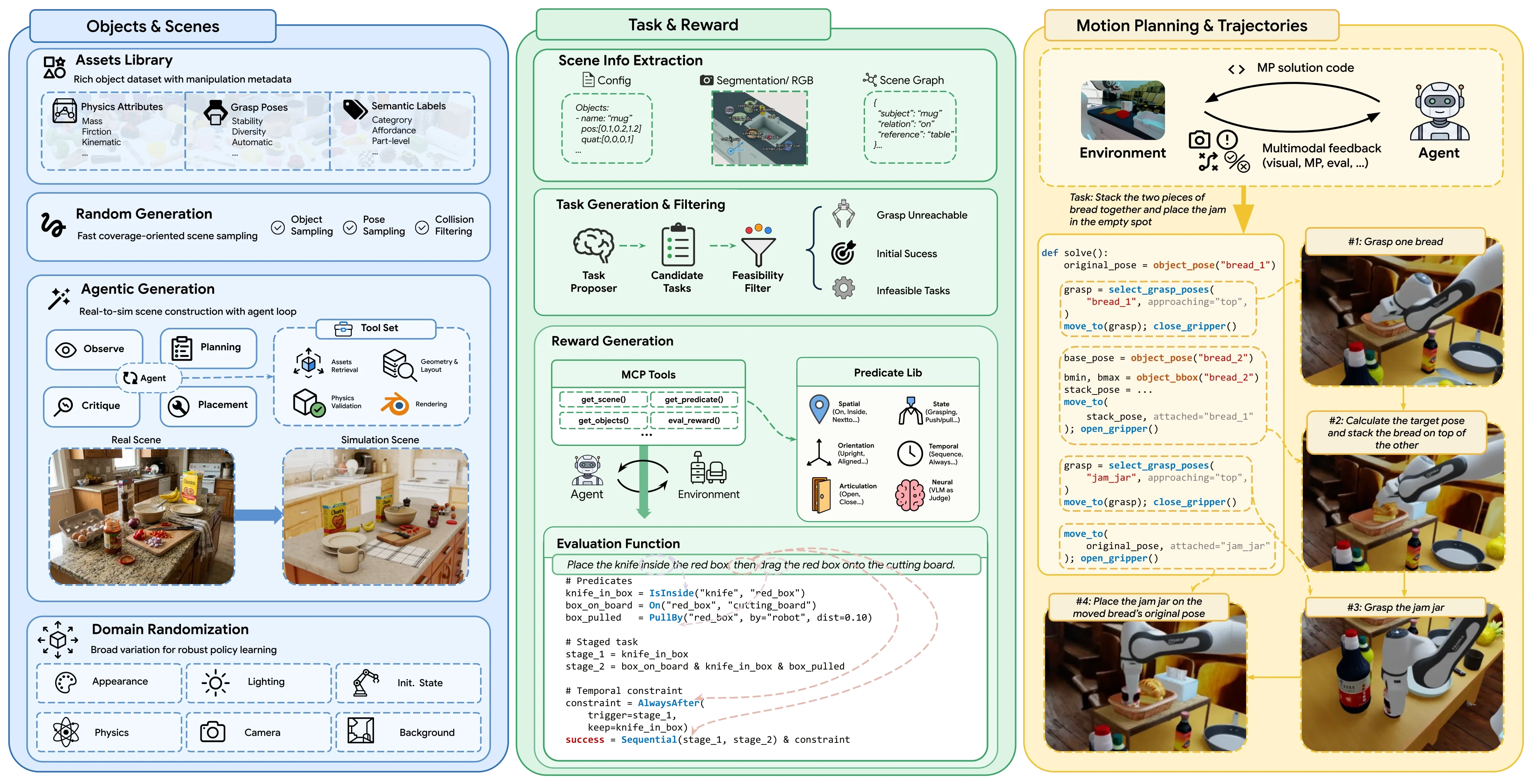
Recent systems such as GenSim2, RoboTwin, InternData-A1, and MolmoBot show that scalable robot data is becoming a central path toward general-purpose manipulation [7][8][9][10]. RoboInF addresses this by coupling five generation stages into a single pipeline: scene construction, task proposal, reward synthesis, motion-code generation with simulator feedback, and domain-randomized rollout with automatic success filtering. Every retained trajectory has been verified against a generated reward function before it enters the training set.
Five generation stages, one training-data output
Each stage produces an artifact that makes the next stage more reliable. The endpoint is not a finished model in this preview; it is filtered VLA supervision containing instructions, observations, actions, and task-success metadata.
- 01Scenerandomized tabletop world
- 02Taskscene-conditioned instruction
- 03Rewardexecutable evaluate()
- 04Programmotion-planning code
- 05Rolloutsuccessful trajectory
- OutputOutputVLA training record
The five-stage generation loop
Scene Generation - Building Diverse Robot Manipulation Worlds
What this stage solves. Robust policies need more than clean tabletop scenes. They need clutter, realistic object co-occurrence, spatial variation, camera changes, lighting changes, and physical diversity.
How it works. RoboInF uses two complementary scene-generation modes. Random synthesis provides broad combinatorial coverage by sampling everyday objects, converting them into simulation-ready assets, rescaling them to plausible physical sizes, and placing them in physics-valid tabletop layouts. Image-conditioned agentic generation helps reconstruct more natural arrangements from reference images, including object and spatial manifests for kitchen-style or household-style scenes.
Across both modes, RoboInF randomizes object poses, camera views, robot initial states, textures, backgrounds, lighting, and physics parameters. The intended distribution is not one perfect simulated world, but many plausible worlds that expose policies to natural visual and physical variation.

Early model observations
We have begun training VLA models on a subset of the generated data. We are not reporting quantitative results in this preview because we want the first published numbers to come with a reproducible benchmark and ablation study rather than preliminary snapshots.
Qualitatively, models trained with RoboInF data handle perturbations (distractor objects, changed lighting, shifted camera poses) more reliably than our internal baselines, and they follow compositional instructions more consistently. We have also seen early signs of zero-shot sim-to-real transfer, which we are working to characterize rigorously.
For this preview, the main contribution is the data engine itself: a way to automatically generate diverse, realistic, controllable, and verifiable manipulation experience at scale. RoboInF is our first step toward scalable robot data generation that is both broad and inspectable, and we are continuing to expand the pipeline across embodiments, richer physical settings, and stronger mixtures of synthetic and real-world data.
Full results, training recipes, and benchmark details will accompany the data and code release.
Current Scope and Next Steps
This preview focuses on scalable, controllable data generation today. The same pipeline points to the next physical settings, embodiments, and data mixtures we are expanding toward.
Citation
If you think this blog post and the content involved are helpful to you, please cite:
@article{roboinf,
title = {RoboInF: Scaling Robot Manipulation Data in Simulation for Embodied Instruction Following},
author = {XLANG Lab},
journal = {xlang.ai},
year = {2026},
month = {May},
url = "https://xlang.ai/blog/roboinf"
}