

"Many years later, as he faced the firing squad, Colonel Aureliano Buendía was to remember that distant afternoon when his father took him to discover ice." —— One Hundred Years of Solitude, Gabriel Garcia Márquez.
When envisioning the future, people have always imagined an intelligent agent capable of following human commands and performing specific tasks, significantly enhancing productivity. In recent times, with the emergence of powerful language models, this vision is accelerating. We're getting a fresh perspective on what language model agents can truly achieve. The language model agent represents a crucial step in this burgeoning field, enabling powerful language models to take actions, use tools, execute various tasks and facilitate more intelligent interactions with humans.
With great excitement, our team, XLang Lab, introduces our recent efforts to exploring and advancing the realm of language model agents. In the upcoming sections, we will elaborate on our mission, workouts, and the outlook for future endeavors. Through our mission, we aspire to humbly provide insightful perspectives on the historical trajectory of this captivating vision, pushing forward the frontiers of what these agents can achieve. With this enthusiasm and determination, let us together embrace a new era of intelligent agents for the future.
What is XLang?
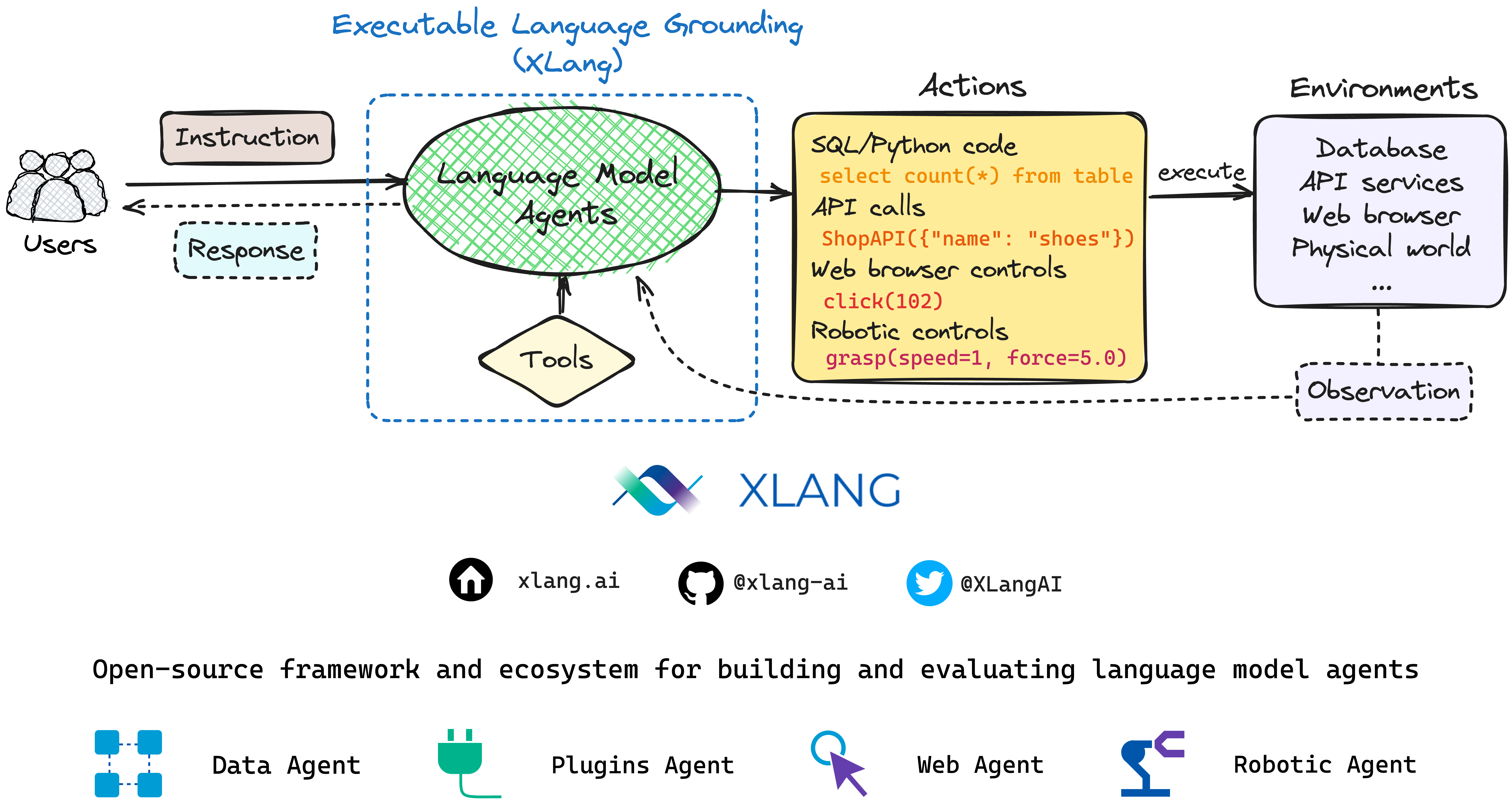
Executable Language Grounding (XLang) refers to the process of converting natural language instructions into code or action sequences executable in some environments. It involves generating code or actions that can interact with the environment, perform specific operations, and produce tangible results. XLang thus serves as a bridge, transforming natural language instructions into code or actions executable within real-world environments. Such environments include but are not limited to databases, web applications, and the physical world navigated by robots.
"Code never lies, comments sometimes do." —— Ron Jeffries
Imagine the process as the transmutation of human instructions and questions — expressed in everyday language — into machine-understandable actions and code. The machine then executes these within a specific environment, leading to changes in the state of that environment. This change is observed, results are analyzed, and a further cycle of interaction with humans is initiated.
This process expands the capabilities of the agents far beyond those of a conventional chatbot, allowing it to address and serve a much broader scope of tasks and applications. And we believe such process lies at the heart of AI/language agents that interact with various real-world environments via natural language and accomplish tangible tasks for us. Recent advances in Executable Language Grounding incorporate techniques such as LLM (Large Language Models) enhanced with neuro-symbolic tools, code generation or semantic parsing, and dialog or interactive systems.
In the current generation of LLMs, we can furnish our models with an assortment of neuro-symbolic tools to enhance their capabilities. Typical inputs to these models could include language from the user, a toolkit brimming with different tools, and a variety of environments. The outcome is an action or code sequence executable within the corresponding environment, often entailing the use of certain tool APIs.
The process of building such agents often demands considerable effort and collaboration from a dedicated team. This is where XLang comes into play. Our objective with XLang is to establish an open-source framework and ecosystem for building and evaluating these powerful LLM-powered agents.
The Motivations and Challenges behind XLang
Our team's initial spark of excitement came when OpenAI announced the release of code interpreters and plugins. These tools represented live demonstrations of many years of our research in areas such as code generation, semantic parsing, natural language interfaces, and interactive dialog systems. Unfortunately, we couldn't access these tools to experiment with our ideas for improvements. This limitation prompted us to think ambitiously. What if we developed our own open-source code interpreters and plugins, or even a more general agent system and framework? This would not only benefit our team but also other research labs and companies worldwide. By sharing our work, we believe we can contribute to the growth of research and applications in this direction, allowing more people to perform exciting and interesting work on our open-source system. More specifically, by shifting the focus towards interactive and real-time demos, we can:
- iteratively add and improve the agent’s design and working logics, such as integrating more useful tools
- implement robust evaluation procedures for various LLMs (Large Language Models) in a neutral manner; while platforms like Vicuna Arena (chatbots) have served as valuable pioneers in this area, we strive to uncover evaluation metrics tailored specifically for language model agents (chatbots + grounding).
- push forward the agentic model’s training and development; by incorporating comprehensive evaluations and continuously iterating the training process, we aim to uncover the shortcomings of LLMs and make iterative improvements.
In short, by setting the frameworks including a real-time demo, we can further advance the research and development of LLM-powered agents and demonstrate their potential.
All such promising directions requires a critical first step: establishing a unified system that real users can access. However, challenges are many. Setting up agent demos is not as straightforward as simply connecting a chatbox to an LLM. It requires considerable effort, both in terms of engineering and research. The agents need to interact with their corresponding environments and effect changes in those environments. The system must robustly handle all sorts of situations, appropriately manage different possible execution results, and present these outcomes in the correct manner. Ensuring the robustness and scalability of this interaction cycle is a significant challenge.
Historically, NLP has lacked practical system demonstrations like those found in robotics or databases, and has instead focused more on testing against static benchmarks. However, with the advent of large models, we believe the time has come to bridge this gap. Similar to the MineDojo framework in embodied AI and the ManiSkill for robotics, setting up such an agent framework necessitates long-term cooperation among many individuals. Our goal is to see the fruits of our research move step by step towards real-world applications that will, in the not-so-distant future, be used by millions.
Our XLang team of about 15 researchers and developers from various backgrounds including NLP (Natural Language Processing), ML (Machine Learning), HCI (Human Computer Interaction), VIS (Visualization), DB (Database), Full-stack development, UI design, and Robotics have been working full-time on this project since the end of March. We've invested significant effort in addressing these challenges and minimizing the gap between research and the development of real-world interactive agents. We firmly believe in the value of our work and hope our open-source project will attract more researchers, developers, and designers to contribute to this exciting direction.
Why Us? Our Journey
The answer to this question is quite straightforward. Our team is deeply interested in this field, and we've always wished for agents that can help people analyze data without coding, and for more natural language-led interaction modes for webs/apps. This was the primary reason why, in March, our team decided within four days of discussing the concept, to congregate in WeWork Shenzhen and commence full-time work on the project. This dedication has continued for more than four months, and we are committed to the long-term development of this project.
Many of our team members have been consistently drawn to research problems in this direction. Our team comprises professionals with backgrounds in HCI, DB, NLP, visualization, and ML. We have all conducted extensive work on executable language grounding for building LLM-powered AI agents, specifically natural language interfaces for data in databases and webs/apps.
Throughout this process, we have maintained active collaborations with industry players like Salesforce, Microsoft, Amazon, Facebook, Google, especially in the realm of text-to-SQL and code generation. We were also among the pioneers in working with large language models for in-context learning (Selective Annotation), LLM + tool use (Binder), instruction tuning and retrieval embeddings for LLM (Instructor Embeddings), code generation and semantic parsing (Spider, DS-1000, Coder-Reviewer Reranking, UnifiedSKG),and interactive dialog systems (ICL-DST, SParC, CoSQL, NL2Interface). More about our research can be found on our project page.
We are a dedicated research team profoundly invested and interested in XLang and language model agents, particularly those related to data and web/app agents. More XLang, code generation, LLM+tool use, and LLM+robotics paper collections can be found in our ACL tutorial on complex reasoning: LLM+tool use.
XLang Agents: An Introduction
XLang Agents are language model agents developed by our team, aiming to utilize a range of tools to enhance their capabilities, serving as user-centric intelligent agents. Currently the XLang Agents supports three different agents focusing on different application scenarios, including:
- Data Agent: This agent is skilled in data tools, allowing efficient data search, manipulation, and visualization. It excels in code execution for data-centric tasks.
- Plugins Agent: With over 200 third-party plugins, this agent addresses diverse daily life needs, aiding in various tasks.
- Web Agent: Utilizing a Chrome extension, this agent automates web navigation, streamlining browsing to find and access information.
- Robotic Agent: comming soon
💡 We have make all three agents online, just visit 👉XLang Agents and feel free to explore! For more details about XLang Agents, you can also check the official documents in 👉XLang Docs !
Here are some interesting things XLang Agents can do!
Data Agent
Code generation + Data tools = Data Agent!
After selecting certain data tools, the agent can take your request and proactively take actions to fulfill your request.
In the following example, you will see how data agent help you search a dataset, draw an interactive line plot, and finally construct an ARIMA model to perform some prediction.
Plugins Agent
Unleash the power of hundreds of real-world applications through our intelligent Plugins system!
The Agent uses a provided API YAML to intelligently determines the optimal timing and selection of plugins to invoke. Each plugin has been thoughtfully curated to fulfill various requirements across your everyday life situations.
For instance, when traveling to Toronto, it recommends attractions, handles currency conversion, provides weather updates, and suggests clothing, ensuring a hassle-free journey.
Web Agent
Effortlessly navigate the internet with the Web Agent, powering up your browsing experience.
The Web Agent, utilizing a Chrome extension, automates website navigation to streamline browsing and enhance information retrieval. It simplifies the user's quest for pertinent details and desired resources.
Specifically in the following example, the agent extracts movie reviews from IMDb and assists in posting a thread on Twitter. Additionally, our interface facilitates multi-turn interactions, ensuring efficient task completion and enriched user engagement.
By harnessing the power of large language models in conjunction with diverse tools, XLang Agents significantly expand the capabilities of conversational interfaces, offering intelligent assistance that revolves around the user.
Engage in a conversation with our XLang Agents to explore its wide-ranging capabilities further!
What's Next? The Future
Our aim is to build XLang, an open-source ecosystem and community for building and evaluating language model agents. This release will just be the beginning of our XLang open-source journey. In the following months, and beyond, we will be open-sourcing several significant projects, which will include all frameworks, models, demos, code, benchmarks, and more. We hope that in these particular times in NLP, we can enable more people, rather than just a few large companies or closed start-ups, to participate. We envision these initiatives as the starting point to establish a vivid LLM-powered agents, LLM + tool use, and language grounding community, encouraging more people to contribute, develop and perform exciting research based on our work.
- Online demos of XLang Agents
- Framework or toolkits, more sophisticated LangChain for building and evaluating langauge model agents
- Agent demo frontend and backend repos for HCI/VIS + NLP research and developers
- Pretraining actionable and agentic large language models (donation supports welcome!)
- SOTA methods for code generation, general LLMs, and LLMs + tool use for building language model agents
- ……
Acknowledgements
We would like to express our gratitude towards Google Research, Amazon AWS, and Salesforce Research. The gift funds and necessary computational resources generously provided by these awards have given us the capability and resources to implement this project. We also appreciate the invaluable advice we received throughout the process.
Personal Acknowledgements by Tao:
I feel fortunate for the year I spent at UWNLP, which is one of the world's top institutions for NLP research. During this time, I observed the nascent shift towards LLM in NLP. I would like to extend my thanks to Noah Smith, Luke Zettlemoyer, and Mari Ostendorf. The idea of XLang came about from a suggestion Luke made during a meeting in his office.
I would also like to pay tribute to my late Ph.D. advisor, Dragomir Radev. Without him, it's very possible that none of what we are starting today would exist.