


📝Blog: https://xlang.ai/blog/osworld-verified
📊Data: https://github.com/xlang-ai/OSWorld/tree/main/evaluation_examples (same place as before)
👩💻Code: https://github.com/xlang-ai/OSWorld (same place as before)
In April 2024, OSWorld's initial version [1] was released for the first controllable environment to benchmark computer use agents. Over the past year and more, we have been delighted and pleasantly surprised to witness the benchmark and environment's driving impact on the community, the emergence of multiple related works, new directions and testing initiatives from tech giants like Anthropic [2][3] and OpenAI [4], and the birth of new startups [5][6][7], applications and possibilities.
Throughout these 15 months, we have continuously invested in supporting features like Docker, parallelization and developing system images for more platforms, while collaborating with the community to address issues on an ongoing basis.
After 15 months, we are announcing a major improvement and refinement initiative. We have collected, verified, validated, and fixed 300+ pieces of feedback, involving approximately two months of dedicated effort from a ~10-person team. We are now launching OSWorld-Verified - an enhanced version of OSWorld with comprehensive upgrades and refined examples, providing more authentic signals for evaluation and learning based on this foundation.
What follows are our insights from this refinement process, re-evaluation results and current state analysis, a retrospective on computer-use agent evaluation over the past year, and our outlook for the future of CUA evaluation.
TL;DR: Major Upgrade! OSWorld has been enhanced and is now OSWorld-Verified with comprehensive improvements. We've systematically addressed 300+ issues in OSWorld through a comprehensive refinement process. OSWorld-Verified delivers more reliable evaluation signals through improved infrastructure (VMware/Docker → AWS, 50x parallelization) and enhanced task quality (fixed web changes, ambiguity, evaluation robustness). The benchmark remains challenging with significant room for improvement toward human-level performance.
Key Updates:
- Infrastructure: Migrated to AWS cloud for massive parallelization (10+ hours → minutes)
- Task Quality: Fixed 300+ issues including web structure changes, instruction ambiguity, and evaluation robustness
- Evaluation: Established public evaluation platform for verified apple-to-apple comparisons
- Performance: Current leading models show success primarily stems from extensive human trajectory data
Impact: OSWorld-Verified provides the community with a more stable, scalable foundation for advancing computer use agent research and development.
Acknowledgement
Special thanks to the following institutions that provided feedback and participated in the fixes (as well as institutions that provided feedback during the process): MoonShot AI,Human Data, OpenAI, ByteDance Seed TARS, Anthropic, Simular, HKU Data Intelligence Lab
Special thanks to the following students who participated in the specific fixes: Mengqi Yuan, Danyang Zhang, Xinzhuang Xiong, Zhennan Shen, Zilong Zhou, Yanxu Chen, Jiaqi Deng, Tianbao Xie, Junda Chen, Jixuan Chen, Haoyuan Wu.
Special thanks to the following students who participated in running the re-evaluation: Mengqi Yuan, Zilong Zhou, Xinyuan Wang, Bowen Wang.
Why an Update?
Although OSWorld's early infrastructure using virtual machines and Docker theoretically already provided a completely realistic and almost reproducible environment for decentralized evaluation distribution, and we dedicated over 400 man-hours for four rounds of checks before the first release in April 2024, with continuous maintenance investing hundreds of additional hours to ensure quality, we still collected approximately 300 issues pointed out by several institutions.
This made us deeply realize a lesson: providing reliable rewards consumes more human resources than we imagined.
Next, we'll discuss the uncontrollable factors we discovered in actual operations that potentially cause this benchmark's signal to gradually weaken and become chaotic over time:
Unexpected Uncontrollable Uncertainty in (Certain) Environments
Environment Instability and Changes
- Anti-crawling mechanisms and CAPTCHAs: Google search, shopping websites showing "blocked by the website as robot", verification challenges
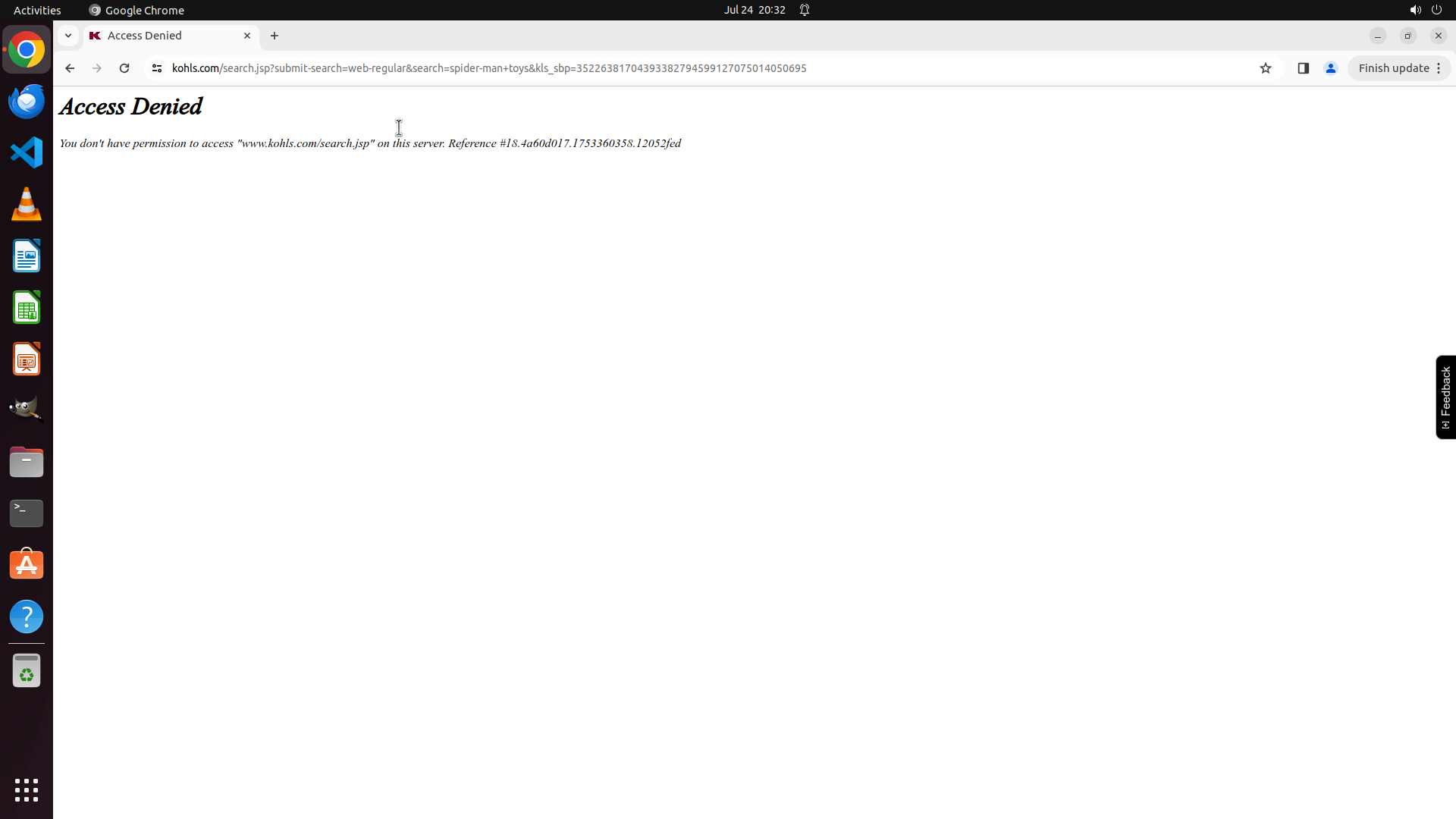
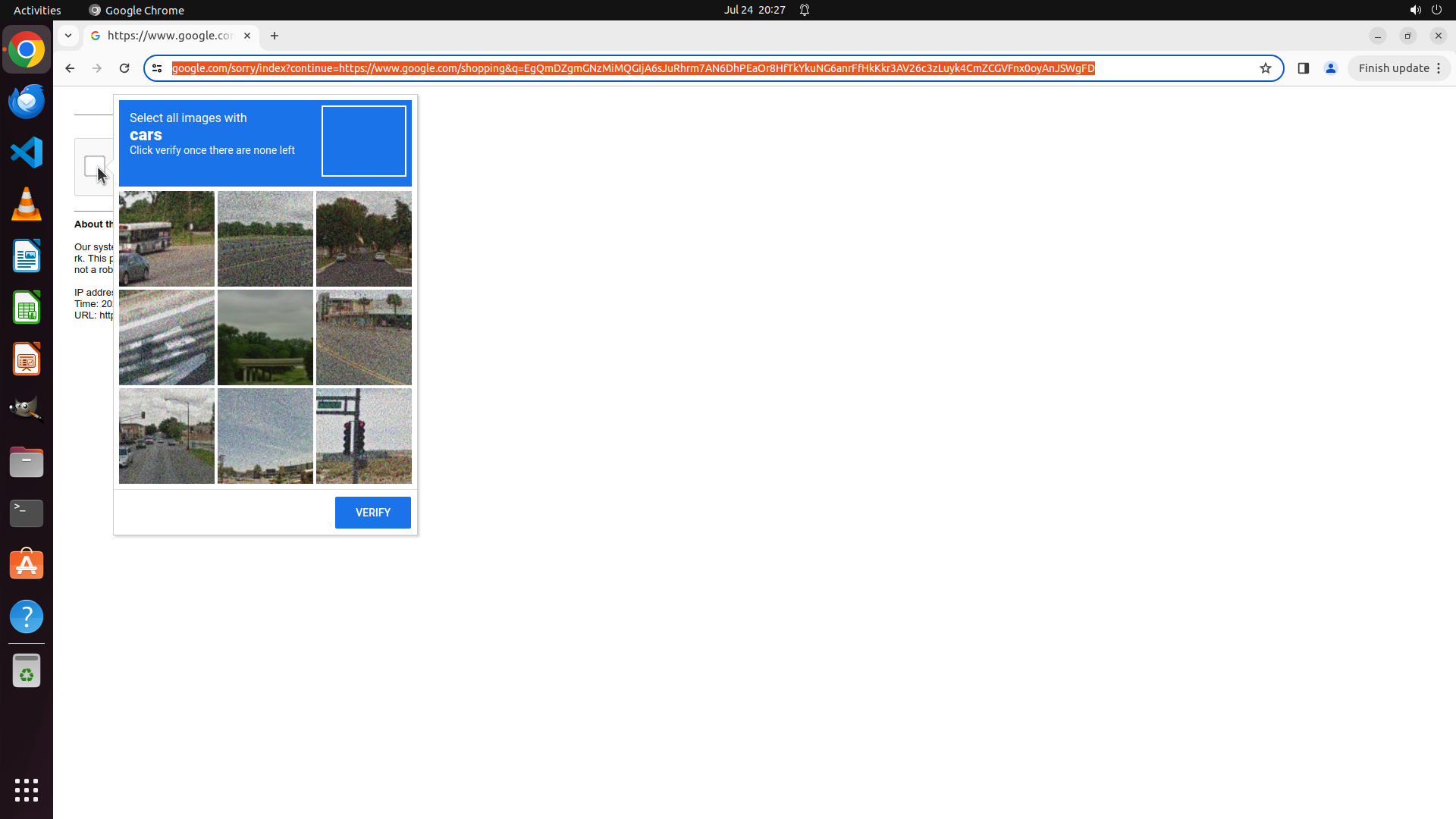
- Network access restrictions: 403 IP blocking issues (Steam connection timeout, NBA.com geo-restrictions)
- Dynamic content changes: Website UI overhauls causing DOM structure changes
- e.g., Apple comparison page URL parameter changes, Budget.com introducing CAPTCHAs from some point
- e.g., Car rental sites (Rentalcars.com) implementing lazy loading and encoding changes
- Web page structure modifications: speedtest.net CSV export exists before while now be deleted, so the task is actually modified
- URL and content evolution: Chrome settings URLs changing, airline sites modifying search interfaces
Fragile Dependencies with Timing Issues
Many tasks exhibit complex temporal dependencies where proper initialization requires precise sequential execution. Software applications and web pages often require significant loading and response times, creating timing-sensitive scenarios that can lead to task failures.
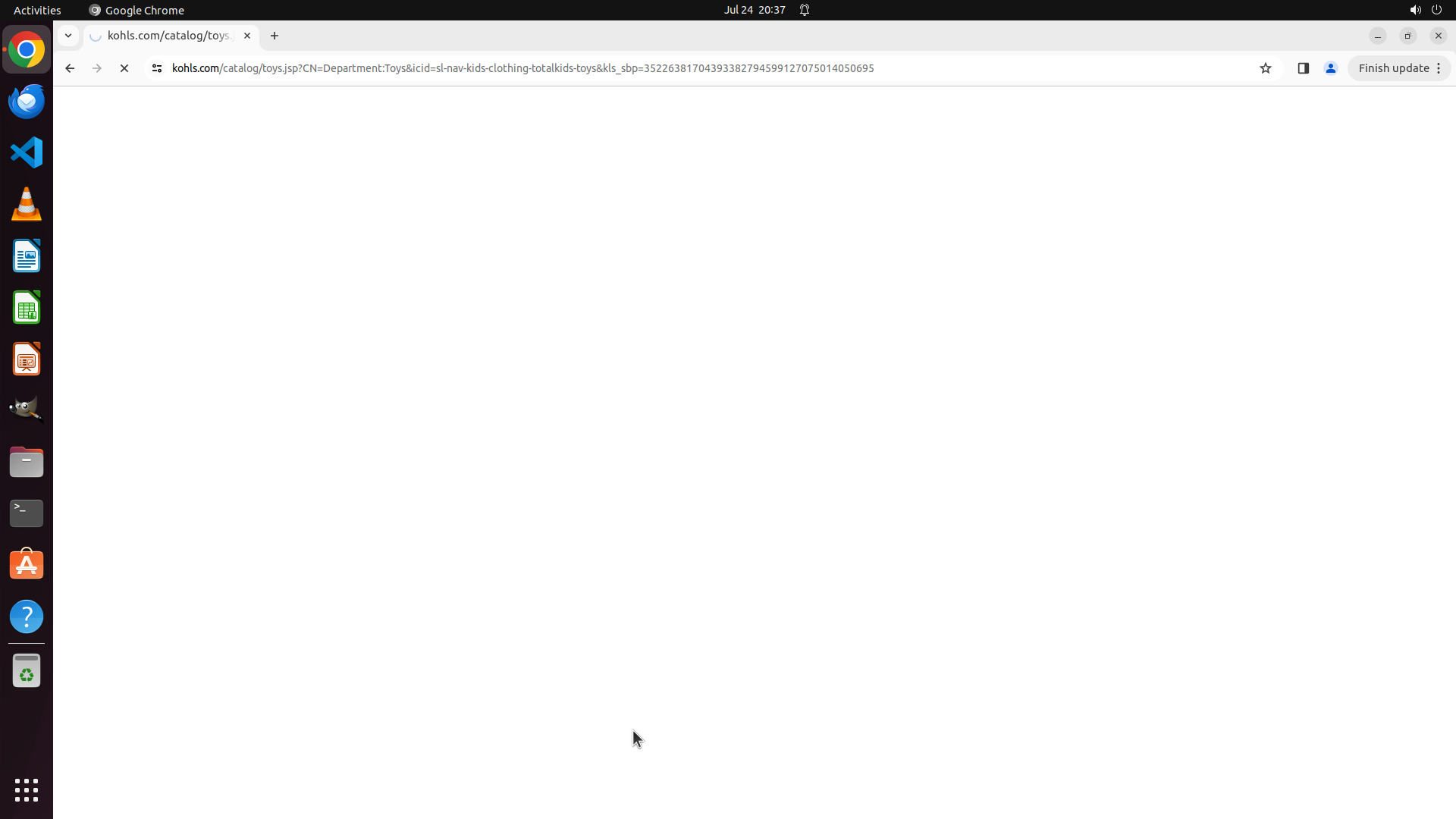
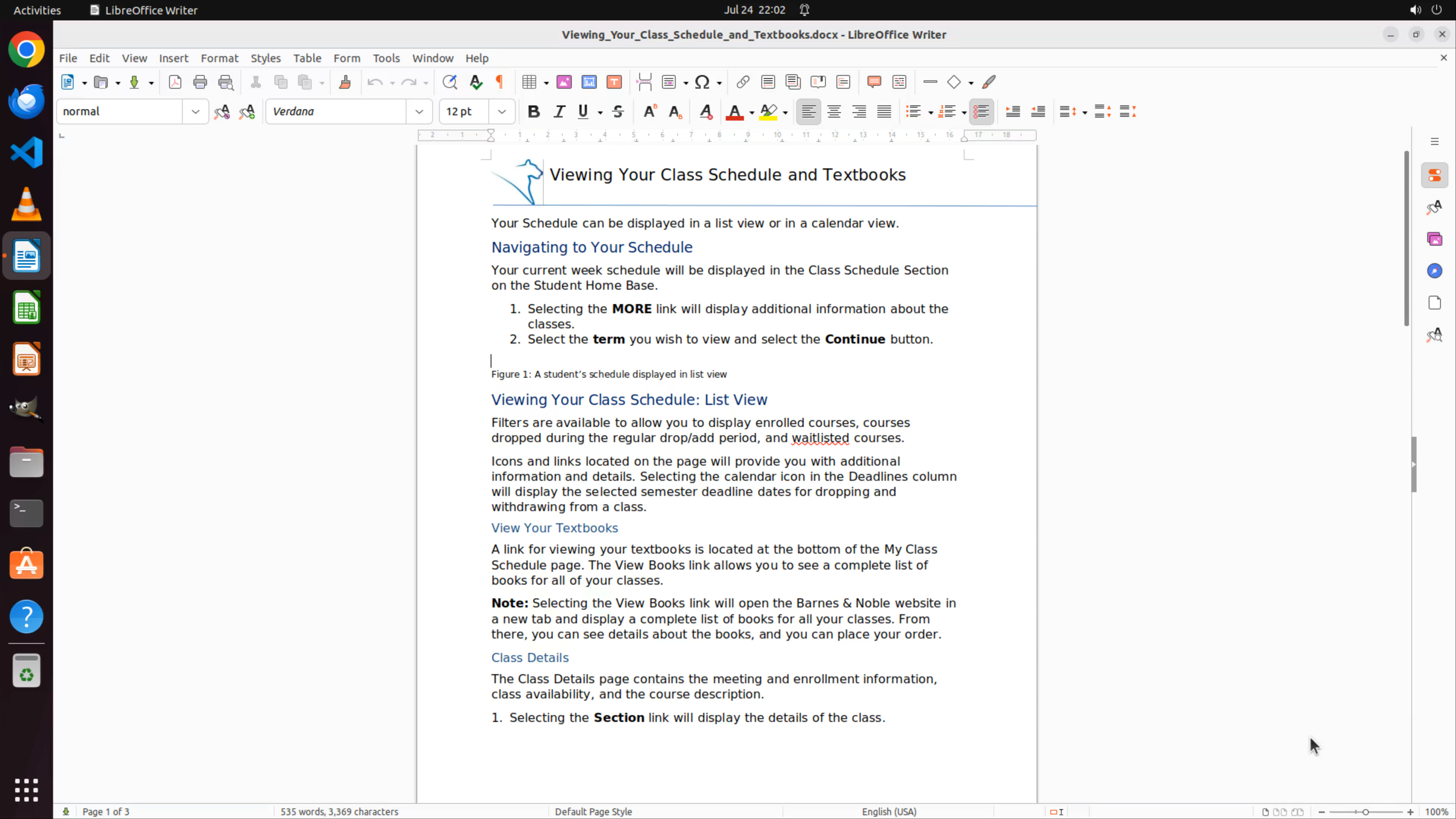
Specific Example: Tasks involving document operations, such as "Copy the screenshot 1.png from the desktop to where my cursor is located," require complex initialization sequences. Our configuration uses pyautogui.press("down", presses=8, interval=0.01) to move the cursor to the 9th line, which demands that LibreOffice Writer be fully loaded with the document open and cursor positioned at the first line before executing this command. These fragile dependencies previously couldn't guarantee sequential execution, causing initial setup failures in multiple tasks.
Incompleteness of Initial Tasks Annotation
Task Ambiguity
Subjective interpretation requirements:
- e.g., "Purple/Red/Green background" having multiple valid interpretations (light purple, dark purple, etc.)
- e.g., "Fill all blank cells" unclear whether referring to all empty cells or specific ranges
Unclear scope definitions:
- e.g., "Resize image" vs "resize layer" confusion in GIMP tasks
- e.g., "Download some image" vs "download some image in GIMP" - the former is feasible while the latter is infeasible, but some tasks failed to clarify this scope
- e.g., When a user says 'Switch off Bluetooth' while Bluetooth is already unavailable (meaning the Bluetooth button cannot be turned on), agents can be confused about whether this should be considered a success or deemed infeasible
Multiple Solution Approaches
Alternative valid methods: Models finding different but correct paths to achieve goals
- e.g., Task instruction is to concatenate two .csv files without specifying how to handle header rows during concatenation, so we must consider every valid concatenation approach and award full points if any method works.
Creative problem-solving: Models using extensions or workarounds not anticipated in ground truth
- e.g., VS Code background customization via extensions when built-in options are insufficient, while we didn't think about this option and marked the task as infeasible.
- e.g., Multi-app workflows when single-app solutions are expected, while we didn't think about this option and marked the task as infeasible.
False negatives from limited ground truth:
- e.g., "Change the first two paragraphs to double line spacing" - the empty line between the two paragraphs can either be set to double spacing or left unchanged; both approaches should be considered correct.
- e.g., Different but functionally equivalent spreadsheet formulas marked incorrect
Decentralized Evaluation Reduces Motivation to Contribute Error Discovery
Lack of motivation to provide feedback: After discovering problems, most people have no motivation to provide feedback to OSWorld for us to make corrections. This leads to gradual evolution where everyone has their own environment, or even modifies tasks for evaluation to achieve higher scores, making scores increasingly opaque and incomparable.
No benefit from submitting modifications: We also see that people hold similar attitudes toward other benchmarks. This is an inherent problem with decentralized benchmarks.
In summary, to advance the development of this field, we hope everyone can achieve apple-to-apple comparisons. Therefore, we hope the community will actively participate in OSWorld-Verified public evaluation while conducting their own tests, running agents on a unified platform for verification. We have made improvements in both infrastructure and tasks.
Infrastructure — From VMware to AWS: The Journey of CUA Environment Infrastructure
The distribution methods for benchmark datasets (similarly, training data) have continuously evolved over time - from being shared through academic papers and word-of-mouth, to university-hosted servers (like Penn Treebank), to GitHub repositories, and now to platforms like Hugging Face datasets as the primary distribution medium.
Computer use agent development environments present unique complexities (after all, we're enabling agents to operate on computers). Under these conditions, achieving apple-to-apple comparisons becomes increasingly challenging, leading to seemingly absurd situations where machine performance correlates with evaluation results.
We have been continuously searching for the technical optimal solution. Our initial attempt involved building controlled environments using VMware, where we distributed .vmdk files and .vmx configuration files, saving images during first-time execution on users' computers. However, this approach had significant drawbacks: despite being theoretically parallelizable, the software consumed substantial personal computer resources with excessive runtime. Additionally, VMware became increasingly closed and cumbersome to download after Broadcom's acquisition.
Inspired by the dokur project series, we integrated Docker containerization technology 2024 Summer, utilizing an open-source VMware-like service - QEMU - running within Docker containers to execute virtual machines. This approach enabled us to achieve multi-environment parallelization on a single server, running 8 or even 16 environments simultaneously for experiments, though still constrained by server performance. We also implemented AWS support during this period but didn't pursue it extensively.
Later, WindowsAgentArena [8] (whose leading authors founded the c/ua company) left a profound impression on us by leveraging cloud services for parallelization, compressing evaluation time from 10+ hours to just 20 minutes. We think it is the right direction, while enhancement can always be done. So we actually followed WindowsAgentArena's approach by leveraging AWS as cloud services and extended this feature in OSWorld infrastructure, which enables us to run up to 50 environments simultaneously and shorten evaluation time to minutes while ensuring comparability across evaluations.

Tasks — Practice for Repairing Task Signals Manually at Scale: Embracing Change and Ambiguity
Over the past month we reviewed and manually fixed nearly 300 feedback items collected from every accessible community channel—Moonshot AI, HUD, OpenAI, ByteDance, Anthropic, and Simular AI, etc. We've compiled the detailed checks and modifications into the following spreadsheet OSWorld fix log.
For tasks we identified as genuinely problematic, we primarily modified only the evaluators to minimize changes to the tasks themselves and maintain score continuity. We only adjusted task descriptions when absolutely necessary.
Major Categories of Issues Addressed
Web Structure and Content Changes
Problem: Websites frequently change their HTML structure, CSS classes, and content, causing evaluation functions to fail or become unreliable.
Solutions Implemented:
- Updated HTML parsing functions: Modified
get_active_tab_html_parseand similar functions to work with current website structures - URL-based validation: Changed from HTML structure validation to URL field validation (e.g., modifying
get_rule_relativeTimefunction) - Fuzzy matching: Added
is_expected_active_tab_approximatefunction for approximate URL comparisons - Environment change marks: Added
possibility_of_env_changefield to flag volatile tasks
Anti-Crawling and Access Issues
Problem: Websites blocking automated access through CAPTCHA, IP restrictions, or bot detection.
Solutions Deployed:
- Proxy infrastructure: Added
proxyfield support for websites with aggressive anti-crawling - Alternative website selection: For heavily protected sites (e.g., SeatGeek → Ticketek, TripAdvisor proxy issues), switched to functionally equivalent alternatives
- Fixed IP allocation: Implemented single-IP assignment for tasks requiring human verification
- Simulated environments (WIP): Created controlled web pages for tasks affected by external dependencies
Time-Sensitive and Booking Tasks
Problem: Tasks involving future dates, reservations, or time-sensitive content become invalid over time.
Solutions Implemented:
- Extended booking windows: Changed booking periods from 4 months to 8+ months for availability
- Updated target locations: Modified unavailable venues (e.g., Albion Basin → Diamond for reservations)
- Instruction clarification: Added specific time qualifications and date ranges
- Dynamic date handling: Improved relative time calculations in evaluation functions
Instruction Ambiguity and Clarity
Problem: Vague or ambiguous instructions leading to multiple valid interpretations and evaluation inconsistencies.
Specific Improvements:
- File format specifications: Added explicit format requirements (e.g., ".png format using only GIMP's built-in features")
- Path clarifications: Specified exact file paths and naming conventions
- Action sequences: Clarified step-by-step requirements (e.g., "batch process all images" vs "adjust individually")
- Scope limitations: Added restrictions like "without launching separate web browser" or "using only built-in features"
- Quantitative specifications: Added precise measurements, percentages, and ranges
- Consider more options: Instead of modifying instruction. Add more options into gold solutions, and give full marks once one is satisfied
Evaluation Function Robustness
Problem: Overly strict or inadequate evaluation functions causing incorrect scoring.
Major Enhancements:
File and Content Comparison
- Fuzzy matching for documents: Added
compare_docx_fileswith 0-1 scoring instead of binary - Image similarity improvements: Implemented perceptual hashing algorithms for
compare_pdf_imagesto ignore minor visual differences - PDF content validation: Enhanced PDF comparison with margin and formatting tolerance
- EPUB accuracy calculation: Fixed evaluation logic using averaging instead of problematic multiplication
Spreadsheet and Data Tasks
- Cell format tolerance: Ignored formatting differences that don't affect content (e.g., "$" signs in currency fields)
- Range specifications: Added precise cell range definitions for operations
- Conditional formatting: Improved detection of styling changes vs content changes
- Formula vs value comparison: Enhanced logic to handle both calculated and manually entered data
GUI and Application Tasks
- Color tolerance: Implemented acceptable color variation ranges for visual elements
- Font and formatting flexibility: Reduced strict requirements on default formatting while maintaining core functionality
- Unit conversion handling: Added proper handling for measurement units (cm, px, etc.)
- Case sensitivity management: Made appropriate distinctions between case-sensitive and case-insensitive comparisons
System and Environment Stability
Problem: Tasks failing due to system-level issues, timing problems, or environment inconsistencies.
Infrastructure Improvements:
- Blocking vs non-blocking operations: Converted
open_filefunctions from fire-and-forget to synchronous blocking operations - Sleep timing optimization: Iteratively adjusted inter-action delays for different machine types (
t3.medium,t3.large) - VM Image Optimization: We compressed the virtual machine images (from 50GB down to 25GB) and adjusted the appropriate IOPS ratios to address the slow first-boot performance caused by lazy loading during AWS AMI/EBS snapshot transfers (LibreOffice taking 1 minute to open on first launch was unacceptable), while also reducing costs
- Font installation: Install all fonts for LibreOffice Impress and Writer tasks to avoid formatting issues caused by missing font files.
- Audio/video handling: Added proper audio device configuration (
-aout=dummyfor VLC) and format validation - Hosting Location: We move all files (including init state files used to build the environment's initial state and gold files for result validation) from Google Drive to Hugging Face. Using Google Drive for file hosting proved to be a poor choice 🙃- whenever download counts became too high, it would temporarily block all downloads for everyone, causing evaluation issues. We have migrated all files to Hugging Face datasets for smooth distribution
Takeaways for Future Benchmark Construction
What We Would Do Differently
- Proactive monitoring: Implement webhook-like systems for continuous task health monitoring
- Simulated environments: Build more controlled environments for tasks prone to external changes
- Dual-track evaluation: Maintain both decentralized and centralized evaluation systems
- Resource planning: Budget significantly more time and human resources for ongoing maintenance. Even very daily tasks can contain significant amounts of possible approaches than we can expect at the beginning
Best Practices Established
- Minimal invasive changes: Prioritize evaluation fixes over task modifications
- Comprehensive documentation: Maintain detailed logs of all issues and resolutions
- Community integration: Establish clear channels for issue reporting and collaborative fixes
- Continuous improvement: Regular review cycles with stakeholder feedback integration
This comprehensive repair effort has significantly improved the reliability and validity of the OSWorld benchmark while establishing processes for ongoing maintenance and improvement.
Based on the Rerun Results, How Far Are We From Completing OSWorld?
Our Implementation
For Agent implementation, we have added implementations of Operator, Claude, UI-TARS [9], Qwen2.5-VL [10], Seed-1.5-VL [11], OpenCUA [12] and other models based on the existing agents implementation. We have also integrated advanced agent implementations based on agentic frameworks, such as Agent S[13], Jedi[14], GTA1[15], and others. All agent implementations are placed under mm_agents folder of OSWorld repo.
In the implementation, since many of the above models are not publicly available, for Operator and Claude models, we extensively referenced the implementation of Computer Agent Arena [16], and referenced some usage examples from these providers [17][18][19]. We also conducted repeated validation and calibration of agent performance through preliminary experiments for confirmation.
Key Insights from OSWorld-Verified Results
We ran experiments for each model under different step settings. Here are some takeaways:
OSWorld remains far from saturated with substantial headroom to human-level performance. Despite remarkable breakthroughs, the benchmark continues to present significant challenges. With human performance estimated at ~72% from our original study, the best current systems have now reached 84.4% of human capability (CoACT-1 at 60.76%). The performance distribution reveals distinct tiers with substantial improvements: agentic frameworks now leading at 45-61%, advanced foundation models achieving 35-44%, and specialized models reaching 25-40%. While the gaps between tiers remain significant, the dramatic upward shift across all categories demonstrates accelerating progress. This indicates that OSWorld continues to provide meaningful developmental signal, particularly highlighting the effectiveness of reasoning-enhanced agentic approaches while revealing remaining challenges in areas requiring complex multi-step reasoning, robust error recovery, and dynamic adaptation to interface changes.

Agentic frameworks with reasoning models dominate the leaderboard. Agentic frameworks powered by reasoning models like o3 have achieved breakthrough performance.CoACT-1 leads with 60.76% success rate, followed closely by Agent S2.5 w/ o3 (56.0%) and GTA1 w/ o3 (53.1%). This demonstrates that sophisticated orchestration layers can dramatically amplify the capabilities of reasoning models, even when those models weren't specifically trained for computer use tasks. Interestingly, highlighting the importance of computational resources in achieving strong performance.
General models' capability improvements and reasoning enhancements show exceptional progress in computer use capabilities. Among foundation models, Claude 4 Sonnet stands out with 43.9% performance, significantly outperforming other general-purpose models and even approaching specialized computer use models like UI-TARS (40.0%). o3's performance varies drastically with step budget (9.1% to 23.0%), compared with 5% of GPT-4o, not to mention further integration with grounding model improvements. This all suggests that better pretraining and post-training bringing general scaling capabilities and reasoning abilities (even without any computer-use specific purpose) will potentially help improve computer use agents.
Based on these results, we updated the leaderboard by adding a verified section and setting it as the default display, while also adding links to computer agent arena scores. For future model submissions, we will continue to serve as a verification platform, consistently open-sourcing agent implementations, execution code, reproducible results, and generated trajectories to help the community gain further insights into current capability boundaries and continuously provide reliable evaluation signals.
How to Use and Submit New Results on the Leaderboard
OSWorld-Verified is an in-place upgrade of OSWorld with enhanced infrastructure and improved task quality. You can always still use providers like VMware and Docker with the new task suites. Please compare your OSWorld results with the new benchmark results when running the latest version.
Meanwhile, we have provided a detailed guide on using our AWS-based Public Evaluation platform. You can set up and run your OSWorld-Verified tests on this more controllable platform.
If you want your results to be verified and displayed on the verified leaderboard, you need to schedule a meeting with us (current maintainers: tianbaoxiexxx@gmail.com, yuanmengqi732@gmail.com) to run your agent code on our side and have us report the results.
You need to upload and allow us to disclose your agent implementation under the OSWorld framework (you may choose not to expose your model API to the public), along with a report that allows the public to understand what's happening behind the scenes.
Alternatively, if you are from a trusted institution, you can share your monitoring data and trajectories with us.
Please carefully follow the Public Evaluation Guideline to get results.
Key Insights for the Community: Next Steps Forward
Scaling Computer Use Data Collection and Training
Our analysis of UI-TARS and OpenCUA, currently the most successful models with publicly available technical details, reveals that their success stems primarily from extensive human computer use trajectory data. The existing publicly available trajectory datasets remain insufficient in scale, predominantly focusing on Mobile and Web Agent domains with limited action spaces, indicating that research in this area is still in its early stages [17][18][19].
There is substantial room for exploration in data collection methodologies (including collection tools, annotation frameworks, and potentially viable commercial models), synthetic data generation approaches, efficient utilization strategies, and optimal integration practices across different training phases. Current evidence suggests that diverse, high-quality computer use data, combined with existing model architectures, is sufficient to enable models to develop robust computer use capabilities. Further scaling could involve collecting large volumes of unlabeled trajectories for pretraining phases, while providing more effective signals during post-training to enhance instruction-following capabilities in computer use scenarios. This approach is particularly suitable for broad and diverse tasks, especially in cases where building reproducible environments is challenging, serving as open-loop training that can capture the general patterns of computer interactions across varied contexts and applications.
Scaling Post-Training Signal Enhancement
Jason Wei's blog post on verification asymmetry and its implications for reinforcement learning [20] provides valuable insights that align with OSWorld's approach to leveraging verification asymmetry for signal generation. For broader-scope computer use domains, we encompass both test case verification (similar to SWE-bench) and verification capabilities found in competition mathematics and open-domain QA (such as AIME and GAIA). We collectively term this "verifiable code" or "(dense) reward code," which can often be automatically generated [21][22].
Current models lack robust capabilities for processing trajectories, particularly multimodal ones, making correctness assessment challenging (though human evaluation of computer use actions remains relatively straightforward). If humans establish appropriate scaffolding with well-designed verification code, combined with human-generated operational results for additional validation support, the difficulty of assessment could be significantly reduced or even eliminated. However, building such scaffolding requires domain expertise, and iterating through multiple problem-solving approaches demands practical experience. Our goal should be to advance models to a position where they can autonomously construct this scaffolding—a process requiring iteration but representing our intended direction. Given current cost considerations, this post-training environment construction process should be narrow and deep, targeting the most critical areas. For example, we could build a comprehensive Photoshop-related scaffolding codebase and then massively expand image editing tasks, or we could annotate a complete spreadsheet scaffolding codebase and then annotate a large number of business data analysis tasks. Rather than broadly annotating many scaffolding codebases and then, after consuming significant costs, annotating shallow tasks that waste our investment in this area.
The overall approach is that we propose leveraging the gap in all domains where max(human verification capability, model verification capability) > model generation capability to reinforce or filter synthetically generated data for capability enhancement. This process can be substantially automated or semi-automated [23][24], with existing academic research offering significant opportunities for industrial-scale implementation. Additionally, for existing verifiable rewards, we can build upon current infrastructure to consider process-based approaches for denser reward provision, thereby improving learning efficiency for suitable tasks where critical milestones can be clearly defined.
More Realistic and Controllable Evaluation
In OSWorld's first iteration, we focused on defining task frameworks for computer use agents, standardizing action states, and establishing evaluation environment infrastructure. Through engineering practice, we explored virtualization-based environment construction and backend-driven action execution methodologies. Due to time and resource constraints, we selected commonly used software applications and avoided over-annotating tasks requiring extended completion times, deep professional software expertise, video understanding components, real-time intensive operations, and asynchronous completion scenarios.
Our team is actively working toward releasing an updated version before the end of this fall, addressing these limitations and expanding the evaluation scope.
Looking forward, we envision building the future of digital intelligent agents, providing novel interfaces that liberate human productivity and transform how we interact with computing environments. The convergence of scaled trajectory data, enhanced verification mechanisms, and more comprehensive evaluation frameworks will be instrumental in realizing this vision of autonomous computer use capabilities.
Thanks for getting this far.
References
[1] Xie, T., Zhang, D., Chen, J., Li, X., Zhao, S., Cao, R., ... & Yu, T. (2024). Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments. Advances in Neural Information Processing Systems, 37, 52040-52094.
[2] Anthopic, P. B. C. (2024, October). Introducing computer use, a new Claude 3.5 Sonnet, and Claude 3.5 Haiku. https://www.anthropic.com/news/3-5-models-and-computer-use
[3] Anthropic, C. (2025). 3.7 sonnet and claude code. https://www.anthropic.com/news/claude-3-7-sonnet
[4] OpenAI Operator Team, Computer-Using Agent: Powering Operator with Computer-Using Agent, a universal interface for AI to interact with the digital world. https://openai.com/index/computer-using-agent/
[5] Get started with C/ua, https://www.trycua.com/
[6] The evaluation platform for computer use agents, https://www.hud.so/
[7] A computer for your AI, https://scrapybara.com/
[8] Bonatti, R., Zhao, D., Bonacci, F., Dupont, D., Abdali, S., Li, Y., ... & Hui, Z. (2024). Windows agent arena: Evaluating multi-modal os agents at scale. arXiv preprint arXiv:2409.08264.
[9] Qin, Y., Ye, Y., Fang, J., Wang, H., Liang, S., Tian, S., ... & Shi, G. (2025). Ui-tars: Pioneering automated gui interaction with native agents. arXiv preprint arXiv:2501.12326.
[10] Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., ... & Lin, J. (2025). Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923.
[11] Guo, D., Wu, F., Zhu, F., Leng, F., Shi, G., Chen, H., ... & Wang, W. (2025). Seed1. 5-vl technical report. arXiv preprint arXiv:2505.07062.
[12] Wang, X., Wang, B., Lu, D., Yang, J., Xie, T., Wang, J., Deng, J., Guo, X., Xu, Y., Wu, C. H., Shen, Z., Li, Z., Li, R., Li, X., Chen, J., Zheng, B., Li, P., Lei, F., Cao, R., Fu, Y., Shin, D., Shin, M., Hu, J., Wang, Y., Chen, J., Ye, Y., Zhang, D., Wang, Y., Wang, H., Yang, D., Zhong, V., Charles, Y., Yang, Z., & Yu, T. (2025). OpenCUA: Open foundations for computer-use agents. arXiv preprint. https://opencua.xlang.ai/
[13] Agashe, S., Wong, K., Tu, V., Yang, J., Li, A., & Wang, X. E. (2025). Agent s2: A compositional generalist-specialist framework for computer use agents. arXiv preprint arXiv:2504.00906.
[14] Xie, T., Deng, J., Li, X., Yang, J., Wu, H., Chen, J., ... & Xiong, C. (2025). Scaling Computer-Use Grounding via User Interface Decomposition and Synthesis. arXiv preprint arXiv:2505.13227.
[15] Yang, Y., Li, D., Dai, Y., Yang, Y., Luo, Z., Zhao, Z., ... & Li, J. (2025). GTA1: GUI Test-time Scaling Agent. arXiv preprint arXiv:2507.05791.
[16] Wang, B., Wang, X., Deng, J., Zhong, V., Yu, T., Xie, T., Li, R., Zhang, Y., Li, G., Toh, J. H., Wang, Z., Zhang, Y., Su, Y., & Yang, D. (2025). Computer Agent Arena: An open-source online platform evaluating computer agents in real computer environments. XLANG Lab. https://arena.xlang.ai/
[17] OpenAI CUA Sample App: OpenAI. (2025). OpenAI CUA sample app [Computer software]. GitHub. https://github.com/openai/openai-cua-sample-app
[18] OpenAI Computer Use Documentation: OpenAI. (2025). Computer use. In OpenAI Platform Documentation. https://platform.openai.com/docs/guides/tools-computer-use
[19] Anthropic Computer Use Demo: Anthropic. (2025). Computer use demo [Computer software]. GitHub. https://github.com/anthropics/anthropic-quickstarts/tree/main/computer-use-demo
[20] Xu, Y., Wang, Z., Wang, J., Lu, D., Xie, T., Saha, A., ... & Xiong, C. (2024). Aguvis: Unified pure vision agents for autonomous gui interaction. arXiv preprint arXiv:2412.04454.
[21] Xu, Y., Lu, D., Shen, Z., Wang, J., Wang, Z., Mao, Y., ... & Yu, T. (2024). Agenttrek: Agent trajectory synthesis via guiding replay with web tutorials. arXiv preprint arXiv:2412.09605.
[22] Xie, J., Xu, D., Zhao, X., & Song, D. (2025). AgentSynth: Scalable Task Generation for Generalist Computer-Use Agents. arXiv preprint arXiv:2506.14205.
[23] Jason Wei, Asymmetry of verification and verifier's law, 2025, https://www.jasonwei.net/blog/asymmetry-of-verification-and-verifiers-law
[24] Xie, T., Zhao, S., Wu, C. H., Liu, Y., Luo, Q., Zhong, V., ... & Yu, T. (2023). Text2reward: Reward shaping with language models for reinforcement learning. arXiv preprint arXiv:2309.11489.
[25] Ma, Y. J., Liang, W., Wang, G., Huang, D. A., Bastani, O., Jayaraman, D., ... & Anandkumar, A. (2023). Eureka: Human-level reward design via coding large language models. arXiv preprint arXiv:2310.12931.
[26] Zhong, R., Snell, C., Klein, D., & Eisner, J. (2022). Non-programmers can label programs indirectly via active examples: A case study with text-to-SQL. arXiv preprint arXiv:2205.12422.
[27] Burns, C., Izmailov, P., Kirchner, J. H., Baker, B., Gao, L., Aschenbrenner, L., ... & Wu, J. (2023). Weak-to-strong generalization: Eliciting strong capabilities with weak supervision. arXiv preprint arXiv:2312.09390.
Citation
If you think this blog post and the content involved are helpful to you, please cite:
@article{osworld_verified,
title = {Introducing OSWorld-Verified},
author = {Tianbao Xie and Mengqi Yuan and Danyang Zhang and Xinzhuang Xiong and Zhennan Shen and Zilong Zhou and Xinyuan Wang and Yanxu Chen and Jiaqi Deng and Junda Chen and Bowen Wang and Haoyuan Wu and Jixuan Chen and Junli Wang and Dunjie Lu and Hao Hu and Tao Yu},
journal = {xlang.ai},
year = {2025},
month = {July},
url = "https://xlang.ai/blog/osworld-verified"
}